


Systems & networking
Researching and inventing new technologies for next-generation infrastructures and platforms for sensors, devices and the cloud.

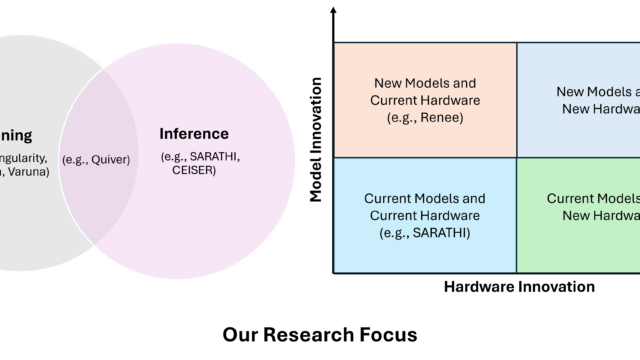

Tool
vAttention
vAttention is a memory manager for KV-cache in LLM serving systems. It decouples the allocation of virtual memory and physical memory using the CUDA virtual memory APIs. This approach enables allocating physical memory on demand…
Publication