


Systems & networking
Researching and inventing new technologies for next-generation infrastructures and platforms for sensors, devices and the cloud.

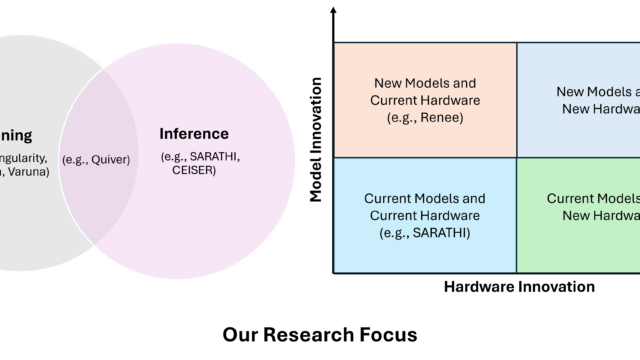

Publication
Towards Safer Heuristics With XPlain
Publication
Reviving Cloud Gaming Sessions
Publication
Input-Dependent Power Usage in GPUs
Tool
RetroInfer
Scalable long-context LLM decoding that leverages sparsity—by treating the KV cache as a vector storage system. RetroInfer is a novel system that rethinks the KV cache as vector storage within a GPU–CPU co-execution setup to…
Tool
AttentionEngine: A Custom Model Optimization Framework
AttentionEngine accelerates transformer attention variants by generating efficient custom kernels, enabling model designers to easily create new variants with our flexible API.