


Computer Vision
Enabling computers and devices to understand what they see.


Video
[VLP Tutorial @ CVPR 2022] Video-Text Pre-training Part II
Learning from Multi-channel Videos: Methods and Benchmarks by Linjie Li, Microsoft Azure AI. VLP Tutorial website: https://vlp-tutorial.github.io/2022/

Video
[VLP Tutorial @ CVPR 2022] Video-Text Pre-training Part I
Overview of Video-Text Pre-training by Kevin Lin, Microsoft Azure AI. VLP Tutorial website: https://vlp-tutorial.github.io/2022/

Video
[VLP Tutorial @ CVPR 2022] Image-Text Pre-training Part III
Advanced Topics in Image-Text Pre-training by Zhe Gan, Microsoft Azure AI. VLP Tutorial website: https://vlp-tutorial.github.io/2022/

Video
[VLP Tutorial @ CVPR 2022] Image-Text Pre-training Part II
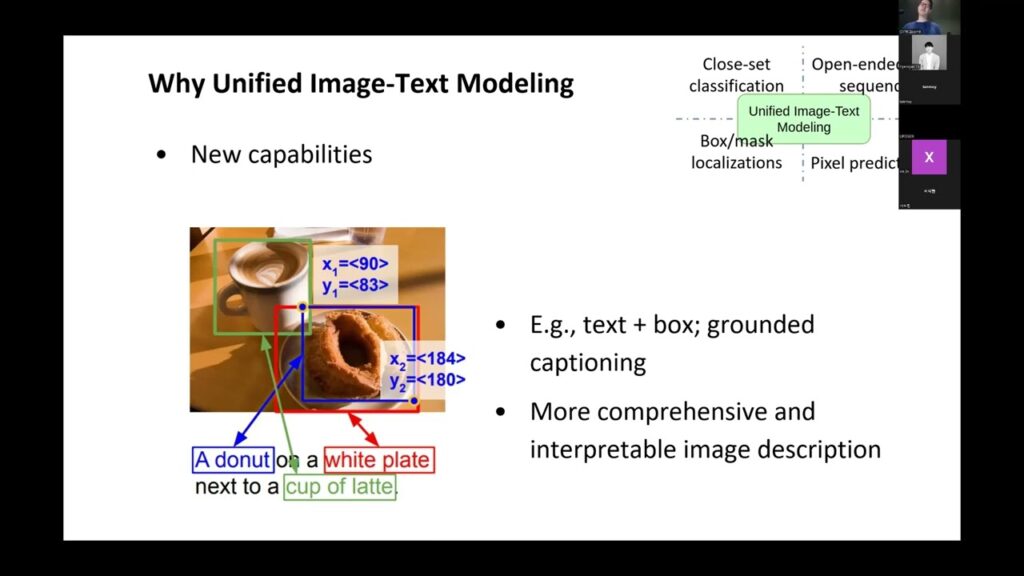
Unified Image-Text Modeling by Zhengyuan Yang, Microsoft Azure AI. VLP Tutorial website: https://vlp-tutorial.github.io/2022/
Video
[VLP Tutorial @ CVPR 2022] Image-Text Pre-training Part I
Overview of Image-Text Pre-training by Jianfeng Wang, Microsoft Azure AI. VLP Tutorial website: https://vlp-tutorial.github.io/2022/

Video
GFlowNets and System 2 Deep Learning
GFlowNets are instances of a larger family of approaches at the intersection of generative modeling and RL that can be used to train probabilistic inference functions in a way that is related to variational inference…

Microsoft Research Blog
Swin Transformer supports 3-billion-parameter vision models that can train with higher-resolution images for greater task applicability
Early last year, our research team from the Visual Computing Group introduced Swin Transformer, a Transformer-based general-purpose computer vision architecture that for the first time beat convolutional neural networks on the important vision benchmark of…